The AI Generated Elephant
published: 2026-05-09
read time: 25 minutes
“AI is a tool, use it or get left behind!” Many of us have already heard this ad-nauseam. This is a “slogan” and it’s a cope. AI is just a tool. It’s not a silver-bullet. It’s expensive, and it’s not as productive as some might lead you to believe. This may seem obvious to some, but not everyone may have the opportunity to research these tools, so not everyone may be aware of how these tools actually work. Regardless of its actual capabilities or the capabilities owners and influencers claim that AI has, this is a labor issue and the data centers that are being built to power these tools are a hazard to our environment. In order to out-maneuver AI companies, who are building AI tools for nefarious purposes, we need to understand it for the cope that it actually is. Its time to address the elephant with two trunks and 3 legs in the room.
How did we get here? 2021 felt like the first real breakthrough in LLM (Large-Language Model) chatbots. By late 2022/early 2023 AI tools were breaking containment and AI was on the minds of the general public. People where already saying that this amazing new tool could write essays for you, that it was the new google, that programming was a solved problem and that clankers were going to take over white color work. A few years later, none of those things happened. What’s the deal? I thought these problems were solved. Yes and no, but mostly no, but kind of yes? More on that later. Regardless of the effectiveness, our big tech overlords have been pushing the narrative that work is “solved” , so that they can control the public’s perception on their products. These AI tools are bleeding money like crazy and they don’t want us to know that. Sensationalizing doomsday narratives about AI gets reactions and clicks from the public and lying about AI’s capabilities gets investments. Ok, so we all know these tools suck, why can’t anyone get a job then? Well, its complicated. The economy sucks right now (this is by design, capitalists love crises) and when that happens labor is slashed, layoffs occur to save plummeting stock prices and to lower expenses, and hiring is slowed or done away with entirely. Nothing new there, except job boards have taken over the hiring process and everyone is making jobs and applying to jobs with LLMs exhausting everything to do with hiring. Additionally, companies are doubling down on AI tools to make up for shortcomings, except they aren’t delivering on their promises. Then why do they keep spending money on it?
Companies are likely aware of AI’s “short-comings” but are investing anyway for the following reasons:
-
They don’t want to lose a competitive edge, so they are trying to stay ahead of the competition by adopting AI tools “early”
-
It’s something to put money in rather than let the money sit still
-
They know AI tools suck, but they are betting on AI tools getting better eventually
The first point boils down to “well everyone else is doing it”. Classic heard mentality in business. The second point is just a business tactic, its especially effective during recessions. Ever notice how the same one trillion dollars keeps getting passed between the same companies? It’s better to circulate money than to let it sit, especially when Uncle Sam is subsidizing AI (I’m sure you know this, but this is usually the telltale sign of a bubble). The third point is worth focusing on a little more. I would argue most companies are aware of what the short comings of these tools are, especially the “agents” or “agentic” tools that tech companies are really trying to sell. It’s the latest and greatest in the snake oil business. Companies investing heavily in AI tools (LLMS, agents, etc) are hedging their bets that it will be good enough eventually, and if they want to get the best return on investment then they have to buy in early. The reality is that if an AI tool is “good enough” and can at least achieve productive parity with a junior level employee, then it will pay for itself and it will be cheaper than any new hire. It appears that companies are definitely trying to fill their gaps with AI tools with varying degrees of success, especially in Tech. Its a factor in why so many Tech/IT workers are flooding the job-market right now. A lot of people are getting laid off from traditional “recession-proof” jobs in addition to a whole generation of “learn to code get a six-figure job” new-grads now looking for jobs in tech. It’s not just tech jobs either, white-collar work as a whole is getting turned upside down. It is likely that “email jobs” will be the first to go.
In reaction to all of this, a lot of content-creators, industry people, etc, have been pushing the “AI is a tool, use it or get left behind” narrative. Fundamentally, they are not wrong about it being a tool with some usefulness (we will explore that more later) but it’s not the tools that are the issue, its the people who own the tools that are. These tools are not created to free us from labor. These tools are created to free companies from labor expenses. “Learn AI” is going to be the new “learn to code” cope. We all know how “learn to code” is going (this isn’t to discourage learning about programming or computer science, it’s just that the ‘learn to code’ to high salary job method is mostly patched, not impossible, just not “easy” anymore). The people pushing the “learn AI” cope typically represent or serve particular interests. I would like to present two groups of “pushers” (there are probably more but this essay doesn’t need to be any longer). The main pushers are the people who own or made the tools in the first place. These are the owners. The owners want more people to use tokens (how businesses “buy” prompts) this means more usage and more dependency on said tools which means more revenue. Nvidia’s CEO, Jensen Huang, went on to say that he would be “alarmed” if his $500k salary engineers don’t use $250k worth of tokens. Hmmm, why would he care about that? Probably because if there is more demand for compute power to supplement the amount of tokens needed to fulfill user requests, Nvidia will sell more H200 GPUs, which are currently powering most AI data centers. Something to think about. The secondary pushers are influencers, they either take sponsor-ships or they are grifters/opportunists who found a way to make money in the chaos. Influencers push a particular narrative to sell courses or to get views. The internet is a very opinionated place, so there will always be contrarians, dissenters, reactionaries, etc, but this particular group is especially nefarious. As we have come to understand in recent years, influencers have a special ability to sway opinions especially in modern times when trust in corporations and government is at a all time low. Influencers feel real and more “human”, and their interactions feel more personal. When people see how successful some of these individuals are and they see how building AI slop, or agents, or some AI Software-As-A-Service tool got them rich, or how vibe-coding xyz got them rich, whatever, it creates a cult of personality around these pushers and the grifts get normalized.
AI Tools in the Field
The biggest question, the one we are all asking when it comes to investigating AI’s capabilities is “Will AI replace my job or X job?” This is a question that is persistent in the minds of both workers and business owners. Workers are anxious and are trying to plan their next move in case AI replaces them. The opportunity to replace workers with an agentic tool to cut costs has business owners and stakeholders foaming at the mouth. As most of us know, some businesses are already shrinking their workforce and using or testing AI to make up for the short-comings. What we are seeing is not full replacement but a slashing of labor across firms. Companies are keeping who they absolutely cannot do without and trimming the fat elsewhere. Those who remain will be given an AI tool or access to some “agentic” service, and they will be asked to do more to make up for the three people on their team that just got let go. Additionally, many companies are laying off large chunks of their US workforce, claiming its to focus on AI to drive investment, and then rehiring cheaper workers abroad (i.e outsourcing). Why would they do that if AI tools are so good? Hmmm. It’s OK though! If you still have your job after your team just got evaporated you have this wonderful bot that uses math to show you the words that make you feel smart! Right? Well, uh maybe?
Previously there weren’t a lot of metrics or research to measure what these things can actually do. AI companies had their own research for their own products that usually involved testing their LLM’s in tightly controlled environments with the purpose of securing investment, not to actually prove their usefulness. If you look into to some of the early tests, like some of the tests created to see how LLMs perform in software development, you’ll find some mediocre results. Many of these tests were spun to look good or to at least claim that in the future it will be good because “look at how much our model improved from the previous one!” Now independent studies are being done. People and businesses are getting serious about seeing what LLM’s can actually do since so much money is being poured into making this thing work but it only kind of works. To no one’s surprise many models fail to complete complex tasks and they don’t offer too much assistance. Most interestingly, using AI as a crutch can also impact skill formation and erode critical thinking skills. Currently a lot of the research looks at different LLM’s capabilities in the “software engineering environment”. Engineers are expensive and if businesses can automate engineers they can most definitely automate other white collar jobs once coding is “solved.” They are certainly trying to make this happen but in truth it might be all smoke and mirrors. For now, companies are merely pushing their existing employees to use LLM’s so that they are more “productive”, but is that true? Are employees learning more and working faster?
How AI Impacts Skill Formation
Lets tackle the assertion that AI will help you learn faster. The idea is that if you learn faster you will be more productive. Learning cannot be delegated as simply getting what you need to do a task. Real learning is the experience of gaining knowledge or a skill and retaining what you learned to form that experience.
The Anthropic Fellows Program, a team of researchers at Anthropic, conducted a study to look directly at how AI affects skill formation. This study is not an independent one, but the conclusions are still interesting. If you give it a read (sources will be linked) there is a lot of entertainment value in how the researchers fight reality to protect Anthropic’s interests, although unintended. Shockingly, researchers found that over reliance on AI tools impacts skill formation. Even researchers at one of the biggest LLM companies cannot deny the impacts these models have on our thinking. The researchers suggest that AI assistance should be carefully adopted into workflows to preserve skill formation. They found that over reliance on AI impairs conceptual understanding and in practice doesn’t actually save time as compared to traditional methods (web searches and reading documentation). Additionally participants that built their skills while using AI did so by only asking the AI conceptual questions, follow up questions, and were generally skeptical of answers. Most notably, researchers cautioned novices against using AI tools because they observed that novice groups in their study compromised their skill formation in favor of using AI to complete tasks faster.
In this study there were 2 main groups and a few sub-groups. Participants were grouped by level of experience, juniors, intermediates, and experts. Those groups were then split into AI assisted and Non-AI assisted. All participants were given a python library to learn (libraries are tools that developers can publish that other developers can implement into their programs to add functionality without having to write code from scratch).The Non-AI assisted groups were allowed to use search engines and documentation. The AI assisted group could use everything. Each group studied the library, submitted new code to a project created for the study and were quizzed on what they learned.
Key Takeaways:
- Most notably the average score difference between the AI group and non-AI group across all skill levels differed by 17%.
- The non-AI group performed consistently better when it came to error-handling & debugging and scored higher on quizzes related to error-handling & debugging.
- Quiz scores and code quality took the biggest hit in the AI group.
- AI and Non-AI groups that exerted a lot of cognitive effort scored the highest and demonstrated skill formation.
- The AI assisted developers that scored high on the quizzes and wrote code with the fewest errors asked the LLM a lot of questions on top of using search engines.
- All high scoring AI assisted developers had to correct AI generated code to some extent.
Put simply, the research indicates that using AI to learn a new skill reduces skill formation. The treatment group (AI assisted) experienced an erosion of many skills (conceptual understanding and debugging skills taking the biggest hits). This suggests that workers should be VERY mindful of their reliance on AI when attempting to acquire new skills. The researchers did not observe a significant improvement in performance (reduced time taken to complete tasks). Using AI improved the average completion time of a task, but the improvement in efficiency was not significant. This is mainly because time was lost prompting and re-prompting for desirable results among the treatment group (AI assisted). The researchers conclude that aggressive AI adoption and incorporation into the workplace can have negative impacts, that contrasting patterns of AI usage suggests that accomplishing a task with new knowledge or skills does not lead to the same productivity gains as taking the time to learn something with documentation or web searches. The researchers cautioned against aggressive AI adoption, but were optimistic about the future. Sure, it might get better, but their findings suggest that current models aren’t anything special. In my opinion, this conclusion was written to shift responsibility to the individual and to not rock the boat at Anthropic. God forbid, a nuanced and purpose built study reveal inadequacies.
Anthropic’s study found that over reliance on AI across all skill levels affected the developer’s ability to formulate skills. OK, so those with less foundational skills might cheat themselves. Surely weathered experts can use these tools to increase productivity, right? Not really. An independent study by METR (pronounced ‘meter’) conducted in early 2025 to explore the impacts of AI on experienced open-source developer’s productivity came to similar conclusions. While the study only makes assertions based on evidence revealed in a particular set of open-source repositories (code bases) with a particular set of developers of a particular skill level (senior level devs with 5 years of experience working with selected open source repositories), the researchers findings were telling. The METR researchers found that when developers are allowed to use AI they took 19% longer to complete their tasks. Developers expected AI to speed up their tasks by 24%. After experiencing slowdowns they thought they worked atleast 20% faster (they felt they were faster just not as much as they hoped). Developers who didn’t have AI tools thought they would work slower, but ended up working faster than the AI group. The researchers recorded the screens of all participants to quantify time spent on tasks and analyzed the slowdowns.
Slowdown Factor Analysis:
- Optimism about usefulness
- developers forecast AI will decrease implementation time by 24%
- developers believed gains where 20% ; time to implement a solution increased by 19%
- High familiarity with repositories
- developers slowed down more on issues they were unfamiliar with
- developers reported that their experience makes it difficult for AI to help them ; AI did not “know” enough
- developers in study had 5 years of experience and 1500 commits on average ; they knew the software well
- Large and Complex repositories
- developers report that AI performs worse in complex environments
- repositories in study average 10 years old with 1M~ lines of code
- Low AI reliability
- developers accepted < 44% of AI solutions
- majority of developers report that they had to make make major changes to clean up AI code
- 9% of time was spent reviewing/cleaning AI outputs
- Implicit repository context
- developers report that AI doesn’t utilize important context.
Even though METR’s study focused on productivity rather than skill formation, similar to Anthropic’s study, the researchers observed all kinds of issues with the LLM’s answers to the participant’s prompts. Solutions were sloppy, they had to be cleaned, more time was spent reviewing their mistakes, etc. Conveniently, the Anthropic study didn’t scrutinize the quality of the output, at most mentioned it in passing. The Anthropic study emphasized individual prompt quality and ‘cognitive engagement’, but what this indicates is that without careful questioning and feeding the LLM proper context, the quality of its answers will suffer. In order to provide meaningful context to the LLM the prompter needs to have an understanding of what it is they are working on and what it is they need help with to get the best output. In other words they have to spend time learning about what it is they are working on. Either way you have to know what it is you are doing. At that point you might as well formulate the skills yourself. If you delegate thinking to an LLM not only will the quality of your work suffer, but you will be removing yourself from the cognitive process. In both studies knowledgeable people wasted time prompting for desirable outputs, or “good enough” outputs that they ended up having to fix anyway. Juniors learned the least in the Anthropic study. If you are a young professional delegating tasks to LLMs, maybe you’re faster, but there is a high chance humans aren’t challenging the LLMs outputs enough and this is what can lead to skill atrophy and we are already seeing it.
A study conducted by MIT attempted to explore the neural and behavioral consequences of LLM-assisted essay writing. The researchers found that LLM’s reduced the friction involved in answering participants’ questions as compared to looking for answers using a search engine, however; this came at a cognitive cost. This cognitive cost was the diminished ability to critically evaluate and or reason with the LLMs output or its “opinions”, in the AI assisted group. The Brain-only (no internet, no AI) group reported higher satisfaction with their work and electroencephalography (EEG) scans of their brains demonstrated higher brain connectivity, compared to other groups. The LLM (AI assisted) group spent less time actually writing and they mostly failed to provide quotes from the essays they “wrote”. The study concluded with researchers strongly suggesting that long-term, in-depth studies are needed in order to fully understand the effects of LLMs on the human brain before we can assert that LLMs are recognized as something that is a net positive for humans.
Moving away from the world of software development, we can find yet another study that is consistent with the findings of aforementioned studies. Some might argue these studies are cherry-picked for the sake of argument. Every source is cherry-picked to suit an argument. Nothing is without bias, but regardless of the position of this essay, these findings are still compelling and are only just the tip of the iceberg. Looking at these studies, there is no denying the drawbacks of LLMs, the research is there, but why are LLMs being shoved down our throats? Why are companies doubling down? Are they really doubling down? The short answer is money, but it’s not profitable. Yet. Companies are doubling down, kinda, but not for reasons that seem rational to us, the people that are footing the bill via tax dollar subsidies.
AI is Expensive
Subsidies
AI companies have been running loses for 5-6 years and that will likely continue. They must make the money back somehow. They will need to keep buying more capital to continue. More data centers, more compute, more ram, more drives, more graphics cards, etc.
AI is highly subsidized. Reports suggests that the cost of compute is being subsized by 10x to 25x. For example, A $200 subscription might come out to $5000 worth of compute. This is an admission of subsidies. They are losing money like crazy. It doesn’t matter though our tax dollars are footing the bill. Soon companies will be forced to pay the real cost or abandon it all together, but many non-AI Companies (let’s call them “AI-Buyers” moving forward) will get locked in to forking up the money as they increase their dependency on LLMs. AI companies are already lowering the performance output because its getting too expensive, so much so even the subsidies are not enough. Even with subsidies, AI-Buyers are spending thousands on tokens per month (tokens are units of data LLMs use to process and understand text, text is data, data processing costs money).
Diminishing Returns
More data; bigger models, but the models aren’t giving the output businesses anticipated. These models are getting “better”, but at a slower rate. This is a big reason why AI companies are pushing so hard for data centers because they are just trying to throw more compute power at the problem. They are trying to brute force their way through the shortcomings. It also goes without being said that these data centers will also be used to store surveillance data. Here is a sidequest for you, look into the data needs of Flock and Palantir, look at who they are doing business with. Anyway, it seems that AI companies are in a burn period, perhaps they are trying to find the negative return point and then once they hit it they can optimize. It’s hard to say right now, but that’s how it seems looking from the outside.
3 Major Components of AI
- Data
- Models
- Time
Data:
The world’s data has already been consumed. We’ll only slowly generate more. Most, if not the entire internet has already been scraped. They are hitting the limit of public data. This is why Oracle’s CEO thinks the only way to push this thing forward is to make private consumer data available, not public, but purchasable. Another issue is that AI is producing content on the internet and the scrappers can’t tell what is human data and what isn’t. You can’t scrape the internet for data anymore if all of the data is AI generated. If AI eats its own shit, then it will hemorrhage when it tries to produce an output.
Models:
Frontier models are between 3 and 5 trillion parameters. Parameters are numerical values that help define a model’s behavior. This many parameters is still not enough to replace engineers and most workers.
Time:
One solution is to loop over a smaller model. Basically, take a prompt, get a response, then take the response and run it against the model again in a loop. Companies will call this “thinking”, but the model is just looping over itself. After the first loop you MIGHT get better results but as you run more loops you get less out of it.
We can’t get more data to keep growing at the same rate. We can get bigger models but they will cost even more. We don’t have infinite time to wait. To keep going (not an endorsement) there would have to be an algorithmic breakthrough AND OR hardware breakthroughs. That could happen tomorrow or in 10 years. You can’t build an industry on something that has not happened yet, but that is what is happening and that is why AI is a bubble and money is being thrown at this problem because of empty promises and its one of the few things holding our economy up.
Predictions
People and companies will drop AI once they have to pay the true cost. In other words, once the subsidies dry up, and they will, people will have to pay the real costs and it will be too expensive.
Consider the formula:
$Price = Profit + Losses + Taxes + Dividends + Capital$
Price = new price AI companies will charge for tokens
Profit = what ever amount greater than the sum of the other variables
Losses = $n$ years of expenses ; at time of writing $n =$ 5 to 6 years
Dividends = money owed to investors, who will demand to be paid
Capital = cost to scale and cost of continued growth
Prices could increase by 30 or 40 times. At the very least 10 to 25 times based on the speculated subsidization factor.
Small, focused models will be the ones that make money.
If this thing is going to continue, if these AI companies want to survive, then AI companies will have to fine tune their models and scale back. The models need to be designed for specific problems. AI companies still need to make back 5-6 years of loses, on top of their other costs, so this is not a guaranteed business model for success. The fact that we are only 5-6 years in to having public models available and so much cash has already been burned and it can only barely do the things investors were promised is concerning. Not because we should consider the needs of investors but when $500 Billion in tax payer dollars (via project stargate) is funding something that doesn’t even work, it’s concerning. To survive, AI companies need to continue to grow, but the costs are already through the roof, the cost to grow will be too much and subsidies won’t last forever. My conclusion is that the AI bubble will pop and it will be nasty. It will pop when the subsidies end. This essay is not advocating for this approach, rather the work that would need to be done to downsize their models enough for AI companies to continue to exist in a world without subsidies should hopefully demonstrate that the way these companies are currently operating is just not sustainable.
The alternative is that AI companies are aware of this, so they want to take advantage of subsidies to lure AI-Buyers in only to pull the rug out from everyone. How will they do this? Well, firms will become overly reliant on AI solutions, a generation of workers will offload tasks to AI agents or tools. AI-Buyers will get locked-in and then boom, the price increases when subsidies run dry or when costs outpace subsidies (this is already happening). AI-Buyers might feel that they are in too deep, it’s too expensive to quit using XYZ agentic service, or that it’s a “sunk-cost”. Either way they will continue to foot the bill, burning money. This will bleed AI-Buyers dry, increasing costs, share-holders will complain and more layoffs will occur due to rising costs. Labor is ALWAYS the first to go when expenses rise because it is one of the highest expenses. “Well, what about Y CEO that did Z to save their workers?” Maybe, there are a few instances of a “benevolent” CEO who promises not to slash labor and instead shaves from the top but that is the exception to the rule. Its not even benevolence, once in a blue moon you get someone who understands the “importance” of long-term, slow growth, over short term gains.
The AI Generated Elephant
Looking at the research, looking at the current and potential expenses of LLMs, there is no way at this moment in time LLMs can continue to prop up the economy and replace the labor force. Unfortunately, that is not something that will be taken into consideration. In fact, companies know this. They are not stupid. They are not omnipotent either, they try things and sometimes they do not work, but the business class has goals that suit their interests and they’re acting to secure their interests with full knowledge of what they are doing. The goal of the business owning class and any business is to grow and continue to generate profits. They will continue to do so even if it means damaging the environment, starting wars, oppressing the working class, etc, etc. To the business owning class it is rational to do so. LLMs are just another means of investment to accumulate growth, to monopolize industries and to punish workers at home & abroad. How do LLMs do these things if the models we have are only so-so at doing real tasks, they fail at solving complex problems, and are so expensive and will only get more expensive?
The real way companies are cutting costs with AI is using it as a cover to layoff all the employees they over-hired during the pandemic only to replace a portion of those employees with outsourced labor, offering displaced workers similar roles with less pay, or by poaching experienced workers and making them work for entry-level wages. Perhaps, AI tools are making up for some gaps, but there’s no way AI tools alone are keeping businesses afloat. Their labor needs are too high, even if they “over-hired” during the pandemic. Therefor, most of the cost cutting measures are, and will be, out-sourcing. Labor needs increased during Covid which led to over hiring, but now expenses have gotten too high, businesses will cut non-vital staff and find out who they really need. Businesses will make up the difference with the experts they kept, re-hire with cheaper outsourced labor, and use some AI tools, AI agents, whatever to fill in the remaining gaps. According to ResumeBuilder in 2024 Google cut core (i.e vital) employees and moved their positions to India & Mexico, 30% of companies with recent layoffs replaced US employees with offshore workers, 24% of companies with recent layoffs plan to terminate and replace US employees with offshore workers in 2025. Customer service roles, tech roles, marketing roles, essentially jobs that don’t need much physical interaction that can be done remotely, will be the most affected. And companies say remote work isn’t practical, no they just wanted their employees to quit in response to Return-To-Office. Now all the people that didn’t quit got laid off. Anyway, that’s a different essay. A quarter of companies that engaged in these practices replaced more than 50% or more of laid off US employees with outsourced labor. All of these projections were made for 2025. ResumeBuilder’s survey was conducted at the end of 2024. All of these things have already happened. With top US companies laying off tens of thousands since 2024, ResumeBuilder’s projections were probably blown out of the water by now. Companies like Facebook (Meta), Microsoft, Google, and the like are announcing layoffs citing initiatives to focus and invest more in AI, the layoffs occur, the stock prices go up only for many of these companies to turn around and go abroad to pay workers of another country less for the same work. The do-nothing liberal columnists over at CNN business, that defend the system tooth and nail, will shake their finger at companies engaging in this behavior. They’ll say how irrational it is, “what a shame”, etc, and nothing more. The reactionary dogs over at Fox news will declare the practices as “Un-American”, they will be blame workers of another country for taking US jobs, they will blame H1B-visa workers all while using racist, white supremacist talking points disguised as populism to rationalize their positions and to fuel “white-replacement” theories, and to divide the working class further. All of this serves as a distraction and AI has generated a grotesque and ugly elephant which has become the best distraction of them all with doomsday theories and the like. What about the real problems AI is creating today and now?
They’re Hunting For Ivory
Looking at the research, it can be concluded that LLMs still have significant short comings. They are capable of doing impressive things, but they do not yet match the output of human creativity when it comes to problem solving, and they do not give experienced workers the gains that they would expect. One thing that was consistent across all studies mentioned in this paper, is that there are real consequences to using this tools and there is not enough evidence to assert that these tools are a net positive to productivity. Now is the time we need to confront these tools for what they are. It’s evident that AI companies don’t want us to understand what it is they are selling and they don’t want us to know how their products work. They want us to worry more about whether or not AI is sentient yet, whether or not its going to blow up the world, and whether or not its a threat to human existence. We need to hold AI companies accountable for the real problems their tools are creating today; such as, misinformation, AI slop, stealing artwork, stealing original creative thoughts and ideas, privacy violations, false arrests, bad medical advice, convincing a teen to commit self harm ending their life, etc, etc, and not the problems they might cause in some abstract future. Sam Altman wants to privatize thinking. They want AI tools to be a utility, like water & electricity. This is obviously sensational nonsense, but trust that people like Sam Altman would foam at the mouth at the money that could be made profiting from a generation of people that have had their critical thinking skills stolen from them. Microsoft claims 20-30% of their top products contain code that is AI generated, whether or not that is true, it shows their intent. Even ignoring all of the spyware, Windows 11 has been a catastrophe of an operating system with terrible performance in touch stone processes that have been historically lean and performance focused, such as opening the file explorer or opening the task bar menu with the windows key. Lest we forget about the recent catastrophic crashes in Windows 11 systems. Not too long ago Amazon Web Services, a cloud computing platform that powers many business applications, completely failed because of an update that contained AI code that wasn’t properly vetted before being approved (a lot of companies lost a lot of money because of this, which is win btw). The list can really keep going, but you would spend more time reading an essay that is already long enough. It’s now more appearant than ever that the pandemic exposed many of the crises of the capitalist system and the business owning class wants AI to alleviate their problems. It’s something to invest in, it’s something to impose austerity with, and most importantly its a distraction to obfuscate responsibility.
AI companies are not omnipotent, they are making mistakes and hedging their bets on profitability. Grow now; worry later. They are not stupid either. Right now, what we are facing is that they know they have hit a limit with the current infrastructure. The dominating belief is to take advantage of the subsidies while they last, and to keep throwing compute power at the problem to force some sort of break through. AI companies wish to throw compute power at iterative models to improve “thinking” while they wait on breakthroughs in hardware or for some genius to write a new revolutionary algorithm. Advancements in algorithms and hardware assume there is infinite time, but there is not. Data centers are tapping our resources and geopolitical conditions are only making things worse. AI itself is not the fundamental problem, but the people who own AI and the associated infrastructure are a threat to labor which is a threat to us, the working class. What we are facing is a potential increase in the depletion of resources and AI focused super data centers, that require more electricity than some cities, are straining our grids, sucking up our water and destroying rural communities and for what? An AI generated slop video? Code that doesn’t even work? In our lifetime we will witness the creation of yet another major threat to our environment, AI super data centers. Aside from the environmental impacts, which could be a lengthy paper in its own right, AI tools still suck ass after billions of tax payer dollars have been flushed down the fucking toilet, but public-free healthcare is too costly. Social services are draining expenses that must be cut and or eradicated. At least we get a stupid fucking picture of a weird ass looking elephant.
In-Summary
- Don’t let AI dull your skills
- Don’t let AI think for you
- Do things the hard and long way
- Prepare to lose that free tier
- Subsidies will end and this thing is going to collapse
- Bubble might pop in the next 5-10 years (or less) without breakthroughs or government intervention
- LLMs are good for breaking down small problems they still can’t do the work of well-trained workers
- LLMs still pose a threat to other working class, white-collar jobs like “email jobs”
- AI tools are a threat to labor and the working class even if they don’t threaten you immediately
- Humans are still needed to solve the complex problems and new problems, but if AI achieves parity with entry-mid level roles there will be problems because there already are problems at this level
Interesting Anecdotes
I’m working as a developer in Korea, and I’ve been seeing a growing trend here as well — many teams are actively trying to build and adopt systems using Claude’s agents and skills. After learning about things like Agents, RAG, and MCP, I started to notice a pattern. A lot of these technologies are presented as productivity or automation improvements, but if you look at the actual architecture, they seem to be designed in a way that increases reliance on LLMs rather than reducing it. For example, agents don’t just “automate” tasks — they break a single request into multiple steps (planning, tool selection, execution, re-evaluation), which often results in multiple LLM calls instead of one. RAG is often described as a retrieval system, but in practice it’s more like a pipeline that prepares better input for the LLM. The final answer is still entirely dependent on the model. MCP also looks like a standardization layer, but essentially it just makes it easier for the LLM to call external tools — reinforcing the idea that the LLM sits at the center of everything. What concerns me is that even a single LLM call is inherently non-deterministic, yet these systems rely on calling the model multiple times in sequence. At the same time, it feels like the pace of improvement in the core LLM models themselves has slowed down recently. So rather than these being fundamental breakthroughs in model capability, it feels like many recent trends are about inserting LLMs into more parts of the workflow and increasing usage frequency. In that sense, it sometimes feels less like “AI getting smarter” and more like “LLMs being used more often, in more places.” - comment from Youtube.
My Background
I feel that is important to share that professionally, I am a software developer. A lot of the perspectives in this paper will reflect that. That is the industry I am in so that is where my views will be coming from. I follow a lot of other developers who care about doing quality work and building systems that work, that are modular, complex, reusable, and maintainable. There is an overwhelming feeling, that after using some AI tools for the past few years, AI tools still cannot reason and solve complex, dynamic problems the way a good engineer can. Why? because complex problems require creative and complex thinking. Software Engineering is so much more than just writing code. Its design, architecture, security, testing, maintainability, I could go on. From what developers have seen, AI can solve small, tightly crafted, low-context problems, like a leetcode problem. Ask AI to build a real piece of software, you get all kinds of problems. Many engineers are beginning to sound the alarm on AI tools. Many companies are using AI tools as a crutch, they are throwing out standards, ignoring security, and opting for quick fixes. They are prioritizing building fast over building something maintainable. This will bite us all in the future. Its hard to say how hard right now, but it will create all kinds of problems, especially when the bubble pops.
“Well I’m not a software engineer, why is this relevant?” We live in a world where the machine has won. Computers do everything for us. Humans still interact with computers and do work on the computer, but the computer still does a lot of the work. Companies want to desperately solve the “software engineering” problem, which is the time consuming process of building software that makes money. Building quality software takes time because all software is unique. There are design patterns that developers follow to ensure maintainability and to solve familiar problems, but ultimately all software is unique because all software has its own set of problems that need solving. If companies can automate that process, if companies can remove developers, think of how much easier it will be to automate the rest of white collar work? That’s what companies want to do, but we are not there yet with this technology. As we can all see they are still trying, or at the very least, companies are using AI as a crutch so that they don’t have to hire more people.
Some have shared that after getting laid off, the same company that laid them off would then reach out and ask them to come back or they would offer them a new position. In most cases, it was part-time work or a role that paid less than their previous role. Most of us, if put in that position, would likely come to the conclusion that the AI tool or whatever “agentic” tool, didn’t pan out or wasn’t as effective, because why else would they be offering me another job so soon? Even if we think the tool wasn’t as effective and now companies are hiring back some of their work force, if you are hired back for less, the company is still saving a buck. They still lowered their costs, which is still what companies want and arguably AI tools are still helping achieve that goal, even if the means to which they achieved that outcome weren’t the desired outcome.
General Notes
Common sense and taste are on the decline.
The emerging skill will be when to use it and when to not. I believe this because companies are getting pushed to adopt LLM services and will force employees to use it because they are paying for the service. It seems in the short term, we will be forced to use it whether we like it or not, or risk scrutiny from management.
Notes On Measuring the Impact of Early-2025 AI on Experienced Developers
When developers are allowed to use AI they took 19% longer to complete their tasks. Developers expected AI to speed up their tasks by 24%. After experiencing the slowdown they thought they atleast worked 20% faster. Developers who didn’t have AI tools thought they would work slower, but ended up working faster than the AI group.
The study does not provide evidence for the following:
- The observations in this study could be applied to the entire IT industry and all software developers.
- AI does not speed up individuals or groups in domains other than software development (this study only looked at SWE)
- AI advancements will not speed up developers in this exact setting in the future.
- There are not ways of using AI more effectively.
In other words, the study is only making assertions based on evidence revealed in a particular set of open-source repositories with a particular set of developers of a particular skill level (senior level devs with 5 years of experience working with selected open source repositories).
Slowdown Factor Analysis:
- Optimism about usefulness
- developers forecast AI will decrease implementation time by 24%
- Post hoc - developers believed gains where 20% ; implementation time increased by 19%
- High familiarity with repositories
- developers slowed down more on issues they were unfamiliar with
- developers reported that their experience makes it difficult for AI to help them
- developers in study had 5 years of experience and 1500 commits on average.
- Large and Complex repositories
- developers report that AI performs worse in complex environments
- repositories in study average 10 years old with 1M~ lines of code
- Low AI reliability
- developers accepted < 44% of AI solutions
- majority of developers report that they had to make make major changes to clean up AI code
- 9% of time was spent reviewing/cleaning AI outputs
- Implicit repository context
- developers report that AI doesn’t utilize important tacit knowledge or context.
Notes On How AI impacts Skill Formation
Overview
The paper argues AI assistance should be carefully adopted into workflows to preserve skill formation. Up to this point, the affects on AI assistance on development of skills has been unclear. After analyzing the effects AI has on skill formation, the researchers concluded that novice workers who rely heavily on AI will compromise their skill formation for productivity. Over reliance on AI impairs conceptual understanding and in practice doesn’t actually save time as compared to using web searches and documentation. Participants that built their skills while using AI did so by only asking the AI conceptual questions, follow up questions, and were generally skeptical of answers. These participants still showed a high level of cognitive engagement.
The researchers found that overall, using AI to learn a new skill reduces skill formation. The treatment group (AI assisted) experienced an erosion of many skills (conceptual understanding and debugging skills taking the biggest hits). This suggests that workers should be VERY mindful of their reliance on AI when attempting to acquire new skills. The researchers did not observe a significant improvement in performance (reduced time taken to complete tasks). Using AI improved the average completion time of a task, but the improvement in efficiency was not significant. This is mainly because time was lost prompting and re-prompting for desirable results among the treatment group (AI assisted).
The researchers conclude that aggressive AI adoption and incorporation into the workplace can have negative impacts, that contrasting patterns of AI usage suggests that accomplishing a task with new knowledge or skills does not lead to the same productivity gains as taking the time to learn something with documentation or web searches. Furthermore the biggest differences in retention and skill formation was in debugging, a very important skill. The researchers are cautious of AI adoption but ultimately put the responsibility on the individual, and let’s be honest, modern work conditions will push people to choose AI to meet deadlines. We are talking about a messy thing called a human being. Human beings do not behave perfectly every time.
Results
- AI did not significantly improve task completion time.
- AI significantly reduced quiz scores, level of skill formation was reduced
- Average score difference of 17% between AI group and non-AI group.
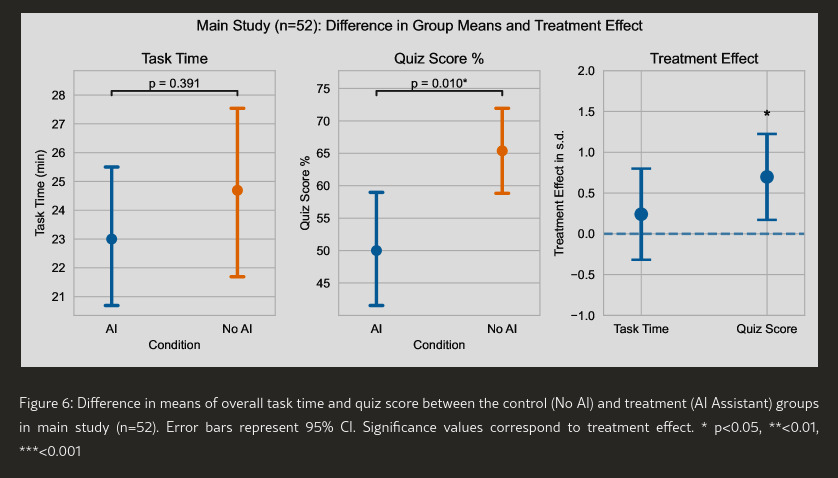
completion time mostly the same, but quiz scores were noticeably different.
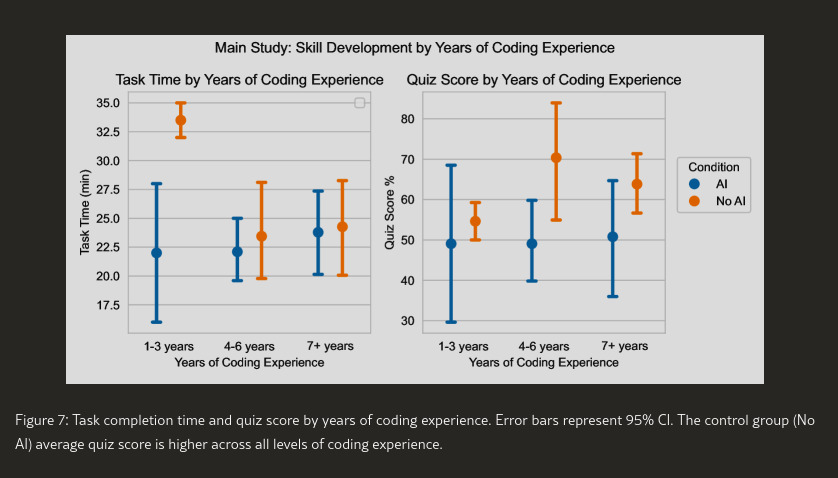
AI did not significantly speed up task completion. In fact, 4/26 members of the control (no AI) did not finish task 2 in the 35 minute time limit, every participant in the treatment (AI assisted) finished task 2, but not much faster than the control.
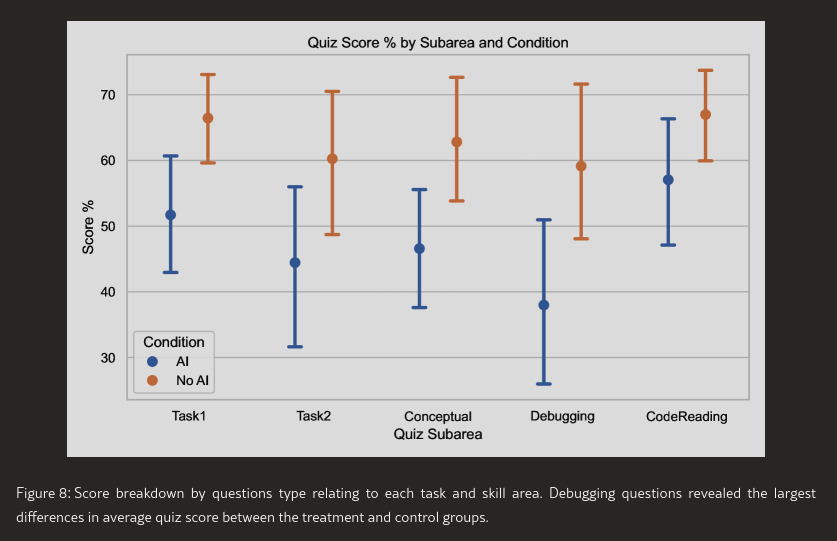
Quiz scores were higher for the control (no AI) in all subareas. It’s important to note that the control (no AI) group performed significantly better in debugging, which is arguably one of the most important skills.
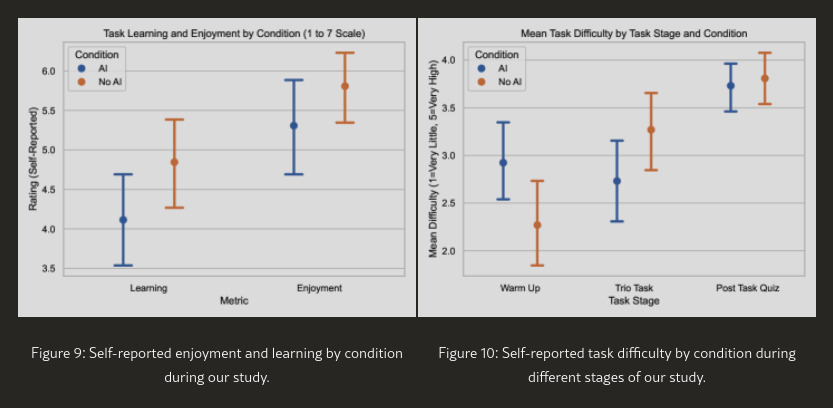
The treatment group (AI assisted) found tasks easier, but found the post-task quiz just as challenging as the control (no AI) group. This suggests that AI gave the treatment group false-confidence.
Qualitative Analysis
In this study each participant was analyzed via screen-recordings. Each recording was annotated by researchers and grouped into categories based on the annotations. The following was revealed:
- AI Interaction Time: lack of speed up can be explained by time taken to prompt, re-prompt, and re-prompt, for a desirable answer. Participants spent up to 11 minutes prompting.
- Query Types: Participants who focused on asking the AI assistant debugging questions or confirmation of “correctness” question spent more time on tasks than those who consulted documentation.
- Encountering Errors: The control group (no AI) encountered more errors but improved their skill by investigating errors and debugging them. Errors included syntax errors and Trio errors. The control group also scored better on debugging questions, because they did the work.
- Active Time: Time spent coding shifted to time spent prompting for the treatment group (AI assisted).
There were 6 interactions patterns that were observed and they can be evenly split into two categories.
Low-Scoring Interactions: Generally involved a heavy-reliance on AI, either through code generation or debugging. Average quiz scores hovered around 40%. Participants in this category showed less independent thinking and more cognitive offloading.
- AI Delegation: participants relied on AI for code generation and task completion. This was the fasted group that experience the fewest errors.
- Progressive AI Reliance: participants started by asking 1 or 2 questions but then delegated all code writing to the assistant. This group scored poorly.
- Iterative AI Debugging: participants relied on AI to verify and debug their code. This group made a higher number of queries and relied on the assistant to solve their problems rather than clarifying their own understanding. This group was slow and scored poorly.
High-Scoring Interactions: Clusters where the average score was 65% (assuming a D-minus is passing) or higher. It can be inferred that treatment participants who scored high did not rely solely on AI and treated output with skepticism.
- Generation-Then-Comprehension: participants in this group generated code and then manually re-wrote the code or copy+pasted the code into their workspace. They then asked the AI follow up questions to gain better understanding. These users were not faster, but scored higher on quizzes than those who blindly accepted all answers.
- Hybrid Code-Explanation: participants in this group composed queries that asked for code generation and explanations of the generated output. They took the time to read the code and explanations.
- Conceptual Inquiry: participants in this group only asked conceptual questions and then relied on their improved understanding to implement a solution for a given task. This group encountered many errors, but resolved these errors independently. On average, this was the fastest among high-scoring patterns and second fastest overall.

This graph suggests that cognitive effort is the best tool for building knowledge and skills. It shows the difference between paste behaviors.
AI-Manual Coding: asking conceptual questions only AI-Code pasting: copying output Hybrid: Both pasting and copying AI-Code Copying: retyping output
Notes On Why AI Is Too Expensive
Subsidies
AI companies have been running loses for 5 years. They must make the money back somehow. They will need to keep buying more capital to continue. More data centers, more compute, more ram, more drives, more GPUs, etc.
AI is highly subsidized. Reports of 10x or 25x. $200 subscription might come out to $5000 of compute. This is an admission of subsidies. They are losing money like crazy. It doesn’t matter though our tax dollars are footing the bill.
Diminishing Returns
More data, bigger models, but the models aren’t giving the output they anticipated. These models are getting “better”, but at a slower rate. This is a big reason why AI companies are pushing so hard for data centers because they are just trying to throw more compute power at the problem. They are trying to brute force the problem. It also goes without being said that these data centers will also be used to store surveillance data. It seems that AI companies are in a burn period, perhaps they are trying to find the negative return point and then once that hit they can optimize? It’s hard to say right now.
3 Major Components of AI
- Data
- Models
- Time
Data:
The world’s data has already been consumed. We’ll only slowly generate more. The entire internet has already been scraped. They are hitting the limit of public data. This is why Oracle’s CEO thinks the only way to push this thing forward is to make private consumer data available, not public, but purchasable. Another issue is that AI is producing content on the internet and the scrappers can’t tell what is human data and what isn’t. You can’t scrape the internet for data anymore if all of the data is AI data. If AI eats its own shit, essentially, then it will hemorrhage when it tries to produce an output.
Models:
Frontier models are between 3 and 5 trillion parameters. It is still not enough to replace engineers and most workers. Companies are already lowering the performance output because its getting too expensive, so much so even the subsidies are not enough.
Time:
One solution is to loop over a smaller model. Basically, take a prompt, get a response, then take the response and run it against the model again in a loop. This is how Deepseek (kind of) produced a competing model with only $6 million USD, but we’ve already reached diminishing returns there. Deepseek has already admitted this. Companies will call this “thinking”, but the model is just looping over itself. After the first loop you MIGHT get better results but as you run more loops you get less out of it.
We can’t get more data to keep growing at the same rate. We can get bigger models but they will cost even more. We don’t have infinite time to wait. To keep going (I am not advocating for this) there would have to be an algorithmic breakthrough AND hardware breakthroughs. That could happen tomorrow or in 10 years. You can’t build an industry on something that has not happened yet, but that is what is happening and that is why AI is a bubble and money is being thrown at this problem because of empty promises and its one of the few things holding our economy up.
Predictions
Source? Me. Also, a YouTube video that I agreed with.
People and companies will drop AI once they have to pay the true cost. In other words, once the subsidies dry up, and they will, people will have to pay the real costs and it will be too expensive.
Consider the formula:
$Price = Profit + Losses + Taxes + Dividends + Capital$
Price = new price AI companies will charge for tokens Profit = what ever amount > the values to the right Losses = $n$ years of losses ; at time of writing $n =$ 5-6 years Dividends = money owed to investors, who will demand to be paid Capital = cost to scale and continue growth
Prices could increase by 30 or 40 times.
Small, focused models will be the ones that make money.
If this thing is going to continue, if these companies want to survive(I am not advocating for this), then companies will have to fine tune their models and scale back. The models need to be designed for specific problems. These companies still need to make back 5-6 years of loses, on top of their other costs, so this is not a guaranteed business model for success. The fact that we are only 5-6 years in to having public models available and this much cash has already been burned and it can only barely do the things investors were promised is concerning. To survive, they need to continue to grow, but the costs are already through the roof, the cost to grow will be too much and subsidies won’t last forever. My conclusion is that the AI bubble will pop and it will be nasty. It will pop when the subsidies end.
The alternative is that AI companies are aware of this, so they want to take advantage of subsidies to lure companies in only to pull the rug out from everyone. How will they do this? Well, firms will become overly reliant on AI solutions, a generation of developers will offload tasks to AI agents or tools. Firms will get locked-in and then boom, the price increases when subsidies run dry or when costs outpace subsidies. Firms might feel that they are in too deep, it’s too expensive to quit using XYZ agentic service, or that it’s a “sunk-cost”. Either way they will continue to foot the bill, burning money. This will bleed companies dry, increasing costs, share-holders will complain and more layoffs will occur due to rising costs. Labor is ALWAYS the first to go when expenses rise because it is one of the highest expenses. Maybe, there are a few instances of a “benevolent” CEO who promises not to slash labor and instead shaves from the top but that is the exception to the rule.
Notes On SWE-CI: Evaluating Agent Capabilities in Maintaining Codebases VIA CI
Overview
Researchers at Alibaba wanted to put LLM’s abilities to do real-world software engineering to the test by seeing if they could throw a bunch of agents at real world repositories to write extensive and maintainable code over the “long term”. The test environment is called SWE-CI, the Software Engineering - Continuous Integration environment. The SWE-CI is a repository level benchmark built upon a Continuous Integration loop in an attempt to shift the evaluation paradigm from static, short-term, functionally correct code to code that is designed to be dynamic and maintainable long-term. The agents will write code, test code, and attempt to maintain the code-bases in an extensive manner over a period of time which is one of the most costly and important SWE tasks by far. The development history of the experiment spans 233 days with 71 consecutive commits.
Extensive experiments across 17 models from 8 providers reveal that current LLMs still struggle to sustain code quality over extended evolution despite accelerating improvements to LLMs. The researchers noted that the SWE-CI powered by different models struggle the most in controlling regressions. The researchers remain optimistic about the future and potential of LLM agents and they hope that their SWE-CI model could serve as a benchmark for coding agents once/if the LLMs improve.
Measuring
Measuring the agent’s effectiveness is done via the following criteria:
- Task Formalization: This is the iterative CI loop. It ensures that the consequences of earlier modifications propagate into subsequent iterations, making the agent’s long-term decision quality observable.
- Normalized Change: A finer-grained metric that reflects the current state of the code-base better than regression testing for functional correctness. The outcome of the normalized change can help the agent determine (in theory) if it introduced a breaking change, rather than focusing on purely passing all test cases. If the normalized change equals 1 then the agent closed the gap ; if the normalized change equals -1 then the agent introduced a breaking change.
- EvoScore: Aggregated single scalar obtained from $N$ iterations on a sequence of codebases ($c1$, …, $cn$) via a future-weighted mean. Better EvoScores result in more maintainable code changes that favor maintainable as opposed to short-term fixes that might break later. In other words EvoScore is used to keep the agents from relying on hacks that solve things merely in the short-term.
Results
The researchers made the following observations to breakdown the results.
1.Code maintenance capabilities of LLMs are advancing at an accelerating pace.
Researchers found that across 18 providers and 8 models there was a consistent pattern: within the same provider family their newer models always scored better. Models released after January 2026 showed the largest gains. This suggests that code capabilities are improving, but this is only relative to models with their product family and other competing models. Refer to the following observations.
2.Different providers place varying degrees of emphasis on code maintainability
When changing the value of $y$ in the EvoScore equation, researchers found when assigning higher weights to the equation by setting $y < 1$, they found models prioritized immediate gains. Conversely setting $y > 1$ later iterations are rewarded, giving advantage to models that prioritize long-term improvement over short terms gains. Researchers found that Kimi, MiniMax, DeepSeek, and GPT all show preferences for long-term gains and stability across different settings. The researchers assert that this illustrates different preferences in training strategies. The relative consistency within each provider shows stable internal training pipelines.
3.Current LLMs still fall short in controlling regressions during long-term code maintenance despite accelerating pace of improvement.
Regression is the core metric for measuring software quality stability over time. If a unit test passes before a code change but fails afterward, the change is considered to have introduced a regression. Regressions don’t always impact users , but could lead to systemic issues later on in development if untreated. The researchers used all of their defined measuring techniques to evaluate the samples that had a “zero-regression rate”. The researchers found that most models scored around .25 while claude opus series exceeded .5. This results indicated that LLMs still struggle to reliably avoid regression in the long-term. LLMs have shown improvements in snapshot-based code tasks (such as leetcode problems or simple functions), but they still face challenges in automated environments and in robust, complex software.
Sources:
Inclusion of sources is not an endorsement of the views of the authors nor the views of the companies they represent. The are merely sources that I vetted that I felt had substance so that I wasn’t making baseless assertions
Academic:
impact of Early-2025 AI on Experienced Open-Source Developer Productivity
How AI Impacts Skill Formation
Professional Opinions:
AI Software Engineers are Too Expensive
How Much Do Tokens Really Cost
Tokens are getting more expensive
Articles:
Google lays off hundreds of ‘Core’ employees, moves some positions to India and Mexico
ResumeBuilder - Offshore Workers 2024
Satya Nadella says as much as 30% of Microsoft code is written by AI